Machine Learning
In this article I will try to explain what is “Machine Learning” ,”How do we categorize it”, “What types of machine learning algorithms” we have, “Differences between machine learning algorithms”, and also I will try to explain briefly “How do they work” with some real usage example of them.In the second part of the article, I will give brief information about some popular machine learning algorithms and their mostly usage areas in the real industry.
Machine Learning is a type of artificial intelligence that allows software to become able to make a prediction of output by using various algorithm via learning from the input training data. To sum up, machine learning is the way to make software find out patterns for the solution by using the trained input data. The algorithm which we use to make software smarter are called “Machine Learning Algorithms”.
Machine Learning Algorithms are often categorized as supervised machine learning algorithms, unsupervised machine learning algorithms, semi-supervised machine learning algorithms, reinforcement machine learning algorithms. Differences between those categories are;
Supervised algorithms require humans for providing training data (which means input and desired output), making some tunes on it, and checking and making the correction according to accuracy.
Unsupervised algorithms do not need to be training with desired outcome data, instead of requiring desired outcome data, unsupervised algorithms use an iterative approach called deep learning to find the most successful pattern which can be used for making predictions. This kind of algorithms is mostly used for more complex tasks according to the supervised algorithms.
Semi-supervised machine learning algorithms are somewhere between supervised and unsupervised machine learning algorithms, these machine learning algorithms use both labeled and unlabeled data for training. Systems or products that use those type of machine learning algorithms are able to considerably improve learning accuracy.
Reinforcement machine learning algorithms are the type of algorithms which interact with its environment by producing actions and find out errors or rewards. Those kinds of algorithms work on based on trial and error searching.
Briefly, we can say that machine learning algorithms are the various approaches for making software to be able to get meaning from data and using this meaning again when needs to make predictions.
Machine Learning
.jpg)
Machine Learning Algorithms searching through data to look for patterns and adjusting actions accordingly, learning processes involved in machine learning are similar to that of data mining and predictive modelling, it means we can say that machine learning algorithms are engines which needed to feed with data, because of that, in most of the cases more data means much more accuracy.
We are so familiar with the machine learning from shopping on the internet (most of the sites suggest us the products which can buy according to our previous purchases, or potentials purchase by looking other similar users purchases), suggestions of extending our network based on people who we may know via 2nd-3rd network connections, sometimes we are getting the benefit of machine learning without knowing them, like spam filters, network security, news feed personalization etc. Machine Learning algorithms take a big part of our daily technology usage, sometimes with awareness sometimes not.
Machine Learning

In the standard approach of programming which I call “Static”, developers have to think about all variants of input, and should develop a product which will give output according to inputs which developers were thinking while developing the products, in most of real cases, when there are some changes on the input (here I don’t mean some series of data with input, I mean all kinds of data which any product needs to be able to work) developers has to refactor their product to make them more suitable for the new type of input.
We can call machine learning as “Dynamic” because of its potential to learn a new pattern from the data for the solution, that’s why it has less limit according to standard approaches, of course it doesn’t mean that we don’t need to change anything on the product which we develop by using machine learning, in any case, we can need to change algorithm itself or support it with other algorithms, but the key point about it is, machine learning willing to learn from the data and able to use it for future data, this makes this approach more dynamic and flexible.
Machine learning algorithms
Below, you can find some machine learning algorithms, I didn’t make any categorization about them while listing, as a general point of those algorithms is they are well known and widely using machine learning algorithms in the industry.
Machine learning algorithms
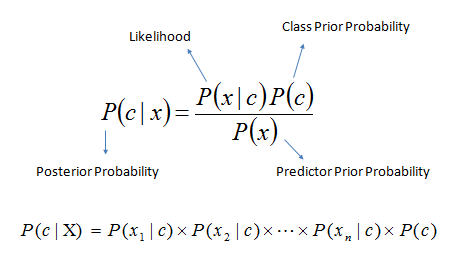
Naive Bayes classifiers are simple probabilistic classifiers based on Bayes’ theorem with nave independence assumptions between the data features.
Real world examples of Naive Bayes classifiers are;
Determining if the email is spam or not spam, classifying articles according to their topic, face recognition, handwriting recognition.
Machine Learning
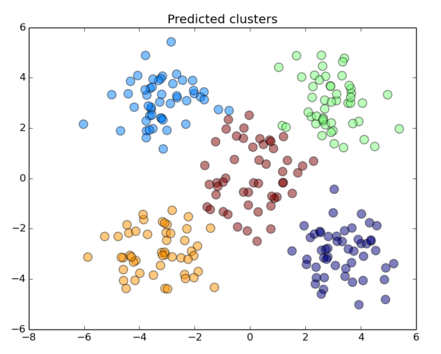
KMeans algorithm is an iterative clustering algorithm that tries to find local maxima in each iteration to be able to make clustering. ”K” is the number of target clusters which algorithm uses for determining total clusters. At the very beginning, this algorithm randomly assigns each data point to a cluster (no specific logic for it), and then starts to compute clusters centroids, according to distance data centroids and clusters centroids, algorithm change member of clusters, every updating process like this requires to compute clusters centroids again, and continue with the same logic for checking centroids for clusters and data points and assign them to nearest cluster according to centroids of clusters. These steps continue until the algorithm reaches to global optima (no further changing member of clusters).
Real world examples of KMeans Clustering are;
Pricing segmentation, server clustering, category segmentation, customer service segmentation etc.
Support Vector Machine Algorithm
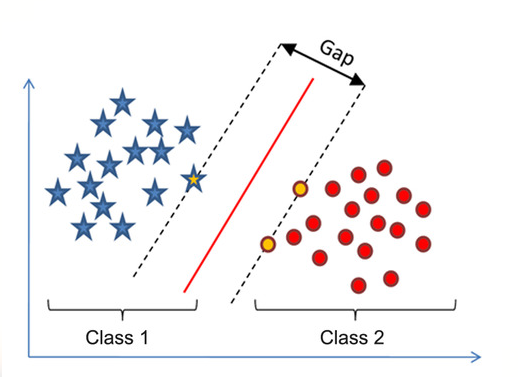
KMeans algorithm is an iterative clustering algorithm that tries to find local maxima in each iteration to be able to make clustering. ”K” is the number of target clusters which algorithm uses for determining total clusters. At the very beginning, this algorithm randomly assigns each data point to a cluster (no specific logic for it), and then starts to compute clusters centroids, according to distance data centroids and clusters centroids, algorithm change member of clusters, every updating process like this requires to compute clusters centroids again, and continue with the same logic for checking centroids for clusters and data points and assign them to nearest cluster according to centroids of clusters. These steps continue until the algorithm reaches to global optima (no further changing member of clusters).
Real world examples of KMeans Clustering are;
Pricing segmentation, server clustering, category segmentation, customer service segmentation etc.
Apriori Algorithm
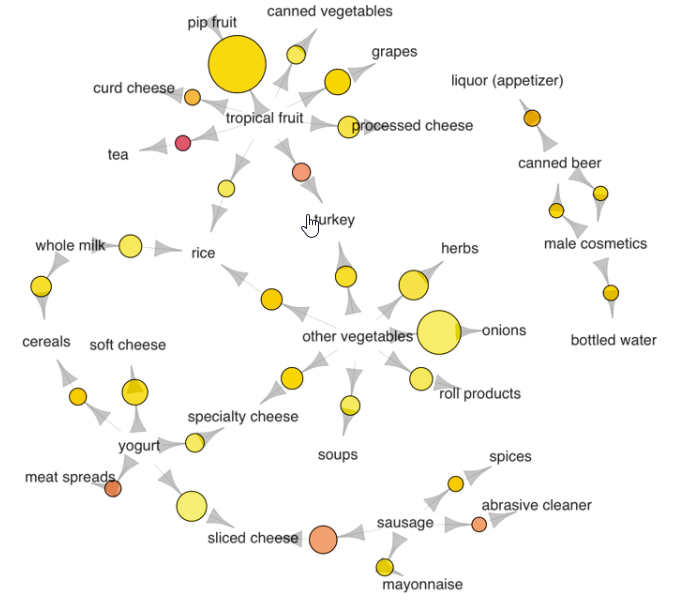
Apriori Algorithm is the algorithm that based on learning association rules by looking through the data, as a simple definition, we can say that this algorithm is checking relations between the data points for learning.
Real world examples of Apriori Algorithm are;
Product suggestions like “Users who bought product X also bought product Z”, or suggesting “Word” while typing etc.
Linear Regression
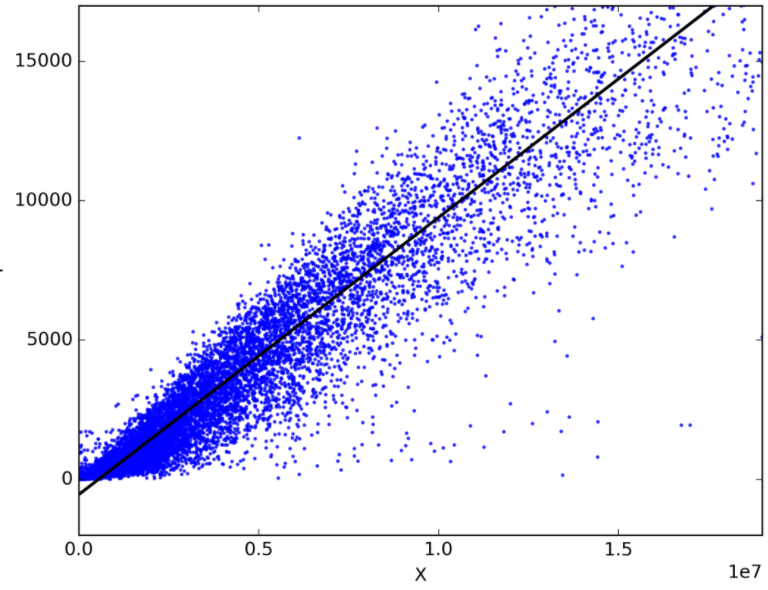
You can find a lot of different names of Linear Regression on the internet, and this can be really very confusing, the reason of that is Linear Regression has been around more than 200 years, this algorithm has been studied almost from every possible angle of it, and each angle has a new and different name.
As the simple definition, we can say that Linear Regression is a linear model which assumes that there is a linear relationship between the input data and single output data, different way to say it, output data can be calculated from a linear combination of the input data.
Types of Linear Regression;
Simple Linear Regression
Ordinary Least Squares
Gradient Descent
Regularization
Real world examples of Linear Regression are;
Impact of products price on sales, time tracking, and productivity improvement etc.
Logistic Regression
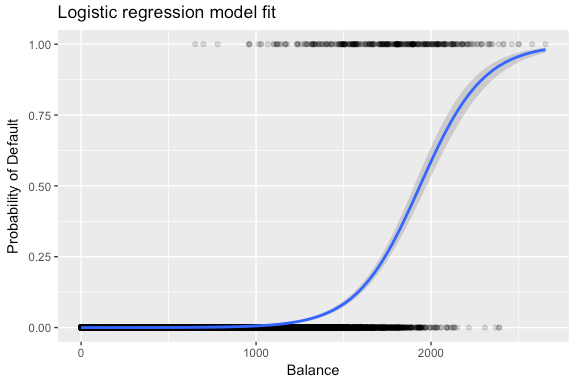
Logistic regression is the machine learning algorithm for classification problems, although its name contains “Regression” it is not the algorithm for regression. Logistic Regression algorithm has a little similar approach to Logistic Regression, it tries to find the function that best describes the relationships between the training input data and the given output data.
Real world examples of Logistic Regression are;
Financial forecasting, software cost prediction, image segmentation and categorization geographic image processing
Artificial Neural Network
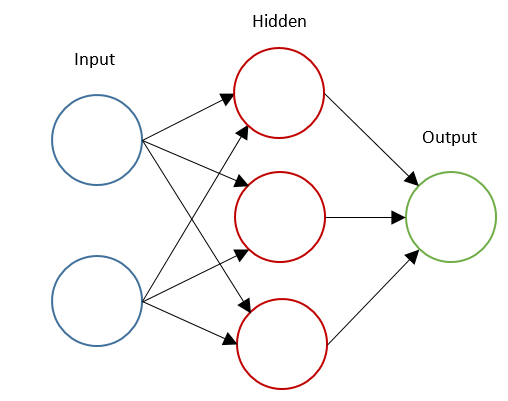
Logistic regression is the machine learning algorithm for classification problems, although its name contains “Regression” it is not the algorithm for regression. Logistic Regression algorithm has a little similar approach to Logistic Regression, it tries to find the function that best describes the relationships between the training input data and the given output data.
Real world examples of Logistic Regression are;
Financial forecasting, software cost prediction, image segmentation and categorization geographic image processing
Random Forests
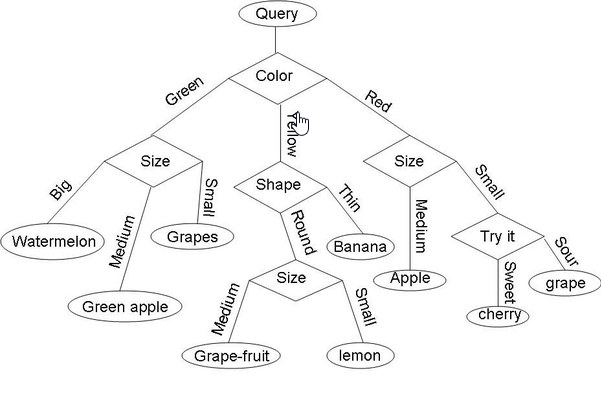
Logistic regression is the machine learning algorithm for classification problems, although its name contains “Regression” it is not the algorithm for regression. Logistic Regression algorithm has a little similar approach to Logistic Regression, it tries to find the function that best describes the relationships between the training input data and the given output data.
Real world examples of Logistic Regression are;
Financial forecasting, software cost prediction, image segmentation and categorization geographic image processing
K-Nearest Neighbors
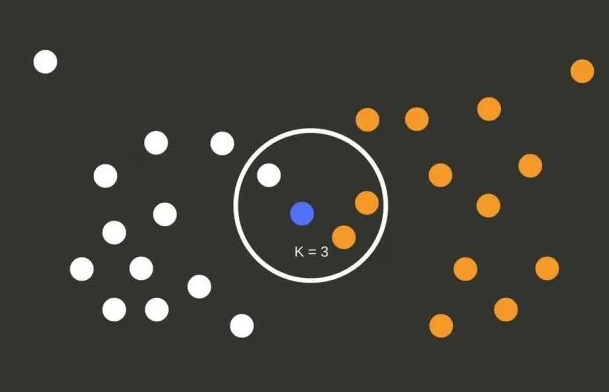
Logistic regression is the machine learning algorithm for classification problems, although its name contains “Regression” it is not the algorithm for regression. Logistic Regression algorithm has a little similar approach to Logistic Regression, it tries to find the function that best describes the relationships between the training input data and the given output data.
Real world examples of Logistic Regression are;
Financial forecasting, software cost prediction, image segmentation and categorization geographic image processing
Thanks for reading.