K-Nearest Neighbor
K-Nearest Neighbor is the one of the well-known and easy machine algorithm which is very suitable for a lot of real-world problems such product recommendation, social media friend recommendation based on interest or social network of person.
What kind of Problems is KNN suited for?
KNN suitable for both classification and regression predictive problems, but it’s using area mostly for classification problems in the industry, but it doesn’t mean that you cannot use it for any other problem except classification, the key point about the machine learning solution is to be able to use data as suitable as possible with the machine learning algorithm, of course this doesn’t mean that you can apply any machine learning algorithm to any data (in fact there is no technical limitation for it, but no grantee that you can get result from this approach).
KNN is a type of instance-based learning or lazy learning, which means action is happening when you what to use it, another way to say it, ‘it doesn’t learn actually’, this feature of KKN brings us some difficulties about using it with big data on the real products, and it pushes us to find alternative way to manage data (simply we can say that because of all calculation is happening when you request solution from the algorithm, the big data which is laying down on the memory can be very serious problem, and finding solution for it also can be real challenge ) , of course there can be some alternatives approaches to get over this problem which we are not going to discuss it today in this article for the sake of simplicity.
After giving brief information about KNN, we can start to see it with details, we’ll then to see how KNN works, how we can use it in real time, and how we can write the code from the scratch to apply this algorithm to any problem which we prefer.
So how does the KNN algorithm work?
Simply we can say that logic of KNN based on “Tell me who your neighbors are, and I’ll tell you who you are”. KNN does some calculation to get the distance between the data points to use that distance to determine who the neighbors are. This calculation means applying “distance metric or similarity function” to the data points (we can say that common choices of usage is Euclidean distance and Manhattan distance)
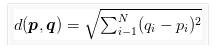
Euclidean distance
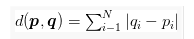
Manhattan distance
There are various distance metric or similarity functions which you can prefer to use according to your data, such as Cosine, Chi-Square, Minkowsky etc.
Before diving in details, shortly let’s talk about what exactly ‘K’ means here. Simply words “K” means that how many neighbors we want to algorithm find for us, or k is therefore just the number of neighbors “voting” on the data. In this article “K” is a bit optional value according to our requirements,
I want to say that when we talk about KMeans Clustering Algorithm which is subject of another article, determining ‘K’ will be important point for the algorithm, but for now, it is not the point of this article.
So now, we can go on;
Ok, let’s take a look how the KNN works in real, below you can find the very simple drawing which shows us spreading blue squares, green circles, and red triangles. (Figure 1)
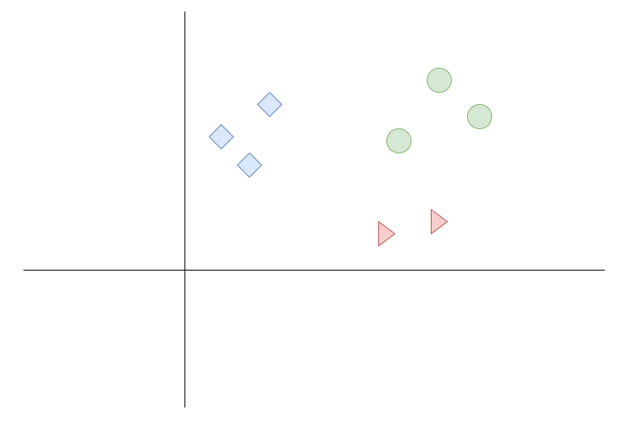
Figure 1
Let’s say we have data point as shown orange star as below (Figure 2), and we want to find the nearest neighbor for it, according to distance formula which we prefer, the algorithm looks through the data and finds the k neighbors.
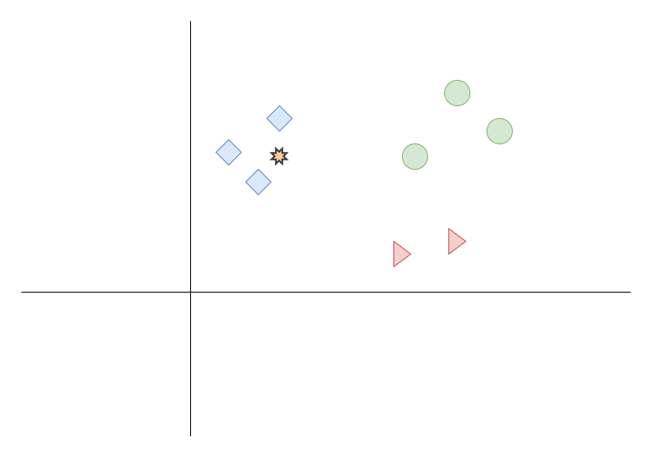
Figure 2
Figure 2
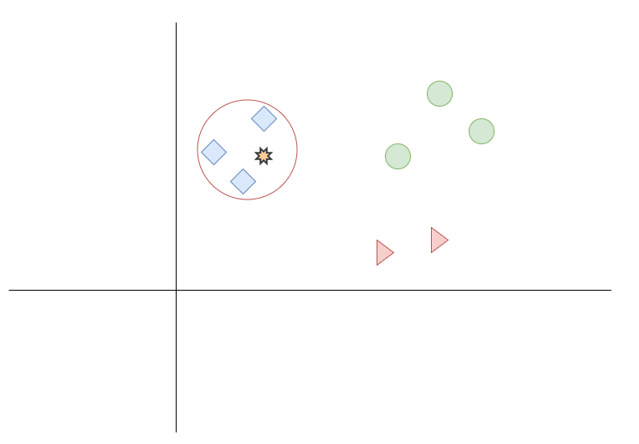
Figure 3
As you can see the logic of the KNN algorithm is pretty simple, nothing so complicated while finding neighbors, only calculating distances between the points and the target point, and getting the amount of them (according to small distance to target point) according to given ‘K ‘ value.
So let’s write some code
Before jumping in writing code, I want to clarify one thing, you can find thousands of articles and posts on the internet which use machine learning algorithm with some machine learning libraries. In this article, I don’t want to do something like that, I don’t want to use any library, not because of I am against to them or not because of I don’t like them, just because of I believe that using any library without understanding “How really does algorithm work” will not be helpful for me neither you in the real world problems, the problems which will be totally different than then standard problems and datasets which are mostly first choice as an example of the most posts on the internet, and I think, to be able to write code from scratch is the way of the real understanding of “How really does algorithm work” and “How to apply it to real world problems.”.
Ok, let’s start!
Before starting writing codes, let's define the simple problem which we can solve by using KNN, let’s assume that we have a website which we publish articles on it, and we want give article suggestions to users about similar articles based the article which they read.
So here, first thing which we need to understand that, we should have data and data features to be able to use it with KNN, in this example our data is our articles, and the features of each article could be, Category, Subcategory, programing language and development platform which each article related with
Here we go;
Data, dataset
Before starting writing codes, let's define the simple problem which we can solve by using KNN, let’s assume that we have a website which we publish articles on it, and we want give article suggestions to users about similar articles based the article which they read.
So here, first thing which we need to understand that, we should have data and data features to be able to use it with KNN, in this example our data is our articles, and the features of each article could be, Category, Subcategory, programing language and development platform which each article related with
Here we go;
Table Development Platform

Table Category
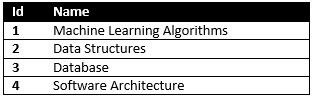
Table Subcategory
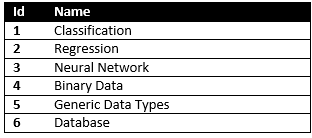
Table Languages

Table Articles
Now, we are ready to start implementation of K-Nearest Neighbor.
The codes which you see below, belongs to one of the my open source machine learning library Ellipses.
IKNearestNeighbour
We need to define two functions, first one LoadDataSet for loading our models with the option of normalization, as the second method GetNearestNeighbors which will look through the data and finds the k neighbors according to model features and k parameter, GetNearestNeighbors has two optional parameters as substractOrigin which means "Do not return the feature data which I pass" and distanceCulculater as the distance function method which we prefer, it is Euclidean distance as default.
using System.Collections;
namespace Ellipses.Interfaces
{
public interface IKNearestNeighbors
{
void LoadDataSet(T[] models, bool normalization = false);
IList GetNearestNeighbors(double[] y, int k,
bool substractOrigin = false, IDistanceCalculater distanceCalculater = null);
}
}
KNearestNeighbour
/* ========================================================================
* Ellipses Machine Learning Library 1.0
* https://www.ellipsesai.com
* ========================================================================
* Copyright Ali Gulum
*
* ========================================================================
* Licensed under the Creative Commons Attribution-NonCommercial 4.0 International License;
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://creativecommons.org/licenses/by-nc/4.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
* ========================================================================
*/
using System.Collections;
using System.Collections.Generic;
using System.Linq;
using Ellipses.Calculaters;
using Ellipses.Helpers;
using Ellipses.Interfaces;
using Ellipses.Metrics;
namespace Ellipses.Algorithms
{
/// ******************Description************************************************************************************************************************************************
/// KNearestNeighbor class is the helper for finding nearest neighbor on the dataset which can be build by
/// given data and its features. Given data can be provided as custom object type,the fields which is/are going to be use as feature for processing
/// should be marked as AiFieldAttribute, other fields which is/are not marked with as AiFieldAttribute will not be processing.
/// There are three distance calculation formulas which can be used for distance calculation Euclidean,Manhattan and Minkowski. It is possible to overwrite or create different
/// distance calculater by inheritancing IDistanceCalculater interface and passing new distance calculater on the KNearestNeighbor constructer or GetNearestNeighbors function.
/// Default distance calculater is Euclidean.
/// *****************************************************************************************************************************************************************************
public class NearestNeighbors : IKNearestNeighbors
{
//Helper class for converting models
private readonly IConverter _converter;
//Helper classes for calculating distance, normalization and converting models
private readonly IDistanceCalculater _distanceCalculater;
private readonly INormalizer _normalizer;
//Flag if the data normalized or not
private bool _dataNormalized;
//Data set as double array list
private double[][] _dataSet;
//Data set as matrix
private Matrix _matrix;
//Data set without convertation as base shape
private IList _models;
///
/// KNearestNeighbour
///
/// Distance calculater
/// Normalizer
/// Converter for the models
public NearestNeighbors(IDistanceCalculater distanceCalculater = null, INormalizer normalizer = null,
IConverter converter = null)
{
_distanceCalculater = distanceCalculater ?? new Euclidean();
_normalizer = normalizer ?? new Normalizer();
_converter = converter ?? new Converter();
}
///
/// Load data set
///
/// Data set
/// Normalize data
public void LoadDataSet(T[] models, bool normalization = false)
{
_dataNormalized = normalization;
_dataSet = _converter.ConvertModels(models);
_models = models;
if (normalization)
_dataSet = _normalizer.Normalize(_dataSet);
_matrix = new Matrix(_dataSet);
}
///
/// Get Nearest Neighbors from the data set according to given data by y
///
/// Data to check
/// Neighbors
/// Return data with origin
/// Distance calculater
public IList GetNearestNeighbors(double[] y, int k, bool substractOrigin = false,
IDistanceCalculater distanceCalculater = null)
{
var distanceHelper = distanceCalculater ?? _distanceCalculater;
var dists = new Dictionary();
var data = _matrix;
var featureLength = y.Length - 1;
var normalizedY = y;
if (_dataNormalized)
normalizedY = _normalizer.NormalizeInput(y);
var inputVector = new Vector(normalizedY);
for (var i = 0; i <= data.Rows - 1; i++)
{
var x = data[i];
var distance = distanceHelper.CalculateDistance(x, inputVector, featureLength);
dists.Add((TObjectType) _models[i], distance);
}
var sorted = dists.OrderBy(kp => kp.Value);
return substractOrigin ? sorted.Skip(1).Take(k).ToArray() : sorted.Take(k).ToArray();
}
}
}
Euclidean Distance
/* ========================================================================
* Ellipses Machine Learning Library 1.0
* https://www.ellipsesai.com
* ========================================================================
* Copyright Ali Gulum
*
* ========================================================================
* Licensed under the Creative Commons Attribution-NonCommercial 4.0 International License;
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://creativecommons.org/licenses/by-nc/4.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
* ========================================================================
*/
using System;
using System.Collections.Generic;
using Ellipses.Interfaces;
using Ellipses.Metrics;
namespace Ellipses.Calculaters
{
public class Euclidean : IDistanceCalculater
{
///
/// Calculate distance with Euclidean Distance
///
/// Data set
/// Data to check
/// Features length
public double CalculateDistance(IReadOnlyList x, IReadOnlyList y, int length)
{
var distance = 0d;
for (var j = 0; j <= length; j++)
{
if (double.IsNaN((dynamic) x[j]) || double.IsNaN((dynamic) y[j])) continue;
distance += Math.Pow(y[j] - x[j], 2);
}
return Math.Sqrt(distance);
}
///
/// Calculate distance with Euclidean Distance
///
/// Data set as vector
/// Vector to check
/// Features length
public double CalculateDistance(Vector vector, Vector y, int length)
{
var distance = 0d;
var x = vector.ToArray();
for (var j = 0; j <= length; j++)
{
if (double.IsNaN((dynamic) x[j]) || double.IsNaN((dynamic) y[j])) continue;
distance += Math.Pow(y[j] - x[j], 2);
}
return Math.Sqrt(distance);
}
}
}
I think we don't need to discuss code here, it simply gets models as parameters, converts it to the two-dimensional array and then applies preferred distance function to the features and finds the how nearest neighbor points according to parameter K.
Anyone who needs Converter Class codes, he or she can download it from Ellipses project page. For the sake of simplicity, I am not going to give that codes here.
So now, let's start to use KNearestNeighbour for our article example.
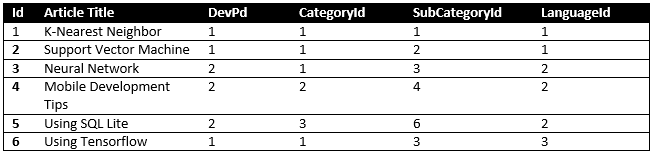
As you remember our Article Table was like below
.png)
It means that we have 4 features for each article which we can feed our KNearestNeighbour class.
Firstly we need to create our model, this model has attribute which is named as AiField (it is the attribute for the converter class to understand which fields of the class are going to be used)
as you can see below, except Id of the article we are going to use all other Ids for the article as data feature.
public class Article
{
public int Id { get; set; }
[AiField]
public int DevPd { get; set; }
[AiField]
public int CategoryId { get; set; }
[AiField]
public int SubcategoryId { get; set; }
[AiField]
public int LanguageId { get; set; }
}
Now let's define a list which we can add our example articles to in it, most of the real cases this step should be done by using a database.
var articles = new List
{
//K-NearestNeighbor
new Article() {Id = 1, DevPd = 1, CategoryId = 1, SubcategoryId = 1, LanguageId = 1},
//Support Vector Machine
new Article() {Id = 2, DevPd = 1, CategoryId = 1, SubcategoryId = 2, LanguageId = 1},
//Neural Network
new Article() {Id = 3, DevPd = 2, CategoryId = 1, SubcategoryId = 3, LanguageId = 2},
//Mobile Development Tips
new Article() {Id = 4, DevPd = 2, CategoryId = 2, SubcategoryId = 4, LanguageId = 2},
//Using Sql Lite
new Article() {Id = 5, DevPd = 2, CategoryId = 3, SubcategoryId = 6, LanguageId = 2},
//Using Tensorflow
new Article() {Id = 6, DevPd = 1, CategoryId = 1, SubcategoryId = 3, LanguageId = 3}
};
and now time to define our KNearestNeighbor class and pass our dataset to it.
var nearestNeighbors = new NearestNeighbors();
nearestNeighbors.LoadDataSet(articles.ToArray());
That's it, we fed our KNearestNeighbor model with our article dataset, and now our model ready to predict the nearest neighbor according to given model features and K value.
Ok, now let's say our user is viewing K-NearestNeighbor article as you are, and we want to suggest similar articles which he or she can be interested in.
To be able to do this, we need to give features of the current article as a two-dimensional array and K value according to how many suggestions we want.
var currentArticle = articles.FirstOrDefault(x => x.Id == 1);
var articleToPass = new double[] {currentArticle.DevPd,currentArticle.CategoryId, currentArticle.SubcategoryId,currentArticle.LanguageId};
and here we are passing our current article to the K-NearestNeighbor model with K=2 value.
var suggestedArticles = nearestNeighbors.GetNearestNeighbors(articleToPass, 2,true);
and here we are passing our current article to the K-NearestNeighbor model with K=2 value.
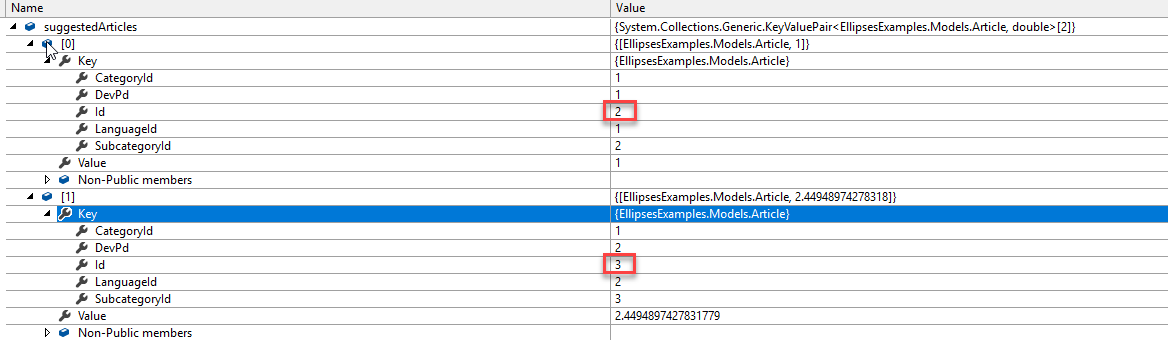
as you can see, the logic and implementation of the K-NearestNeighbor Algorithm are very simple and useful.
Thanks for reading.